TLDR
I explain serialization of JSON data to native cpp objects.
Serialization
JSON has non-primitive data types: arrays, objects. Objects and Arrays can be nested within each other. I could have used the similar technique that I describe in part 1 of this series; that is: have functions taking care of each data entity and they recursively call each other going through the JSON input.

But I wanted to make the parser performant and resilient. Function call adds a bit of overhead. If we define functions for taking care of each entity in JSON, we would end up with a lot of function calls. And on top of that the calls have to be recursive. That means our program becomes dependent on the stack size of the operating system. A JSON input that is heavily nested may cause StackOverflow!
According to the crude test I ran on my Linux machine without changing any stack settings, I got this result.
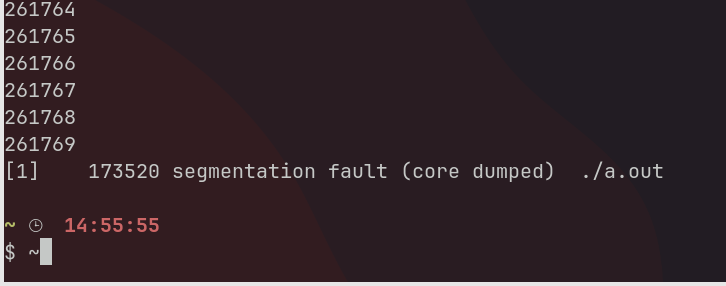
The limit is around 261K recursive function calls. I haven’t seen any JSON file nested on 261K levels but the limit still made me uncomfortable.
I knew that the same effect as recursion can be achieved by keeping track of context in the stack data structure.
I used std::vector to implement the stack. Now, we are limited by the maximum size of the vector container in cpp; that is, the output is given by std::vector::max_size() which on my system came out 1152921504606846975 ~ 10^18. That would serve as a maximum limit approximately for other container types too; which means max such number of array elements.

If we encounter primitive data we pushed it to the mouth which pointed to the top of the stack, else if we encountered a container we updated the stack. And pop from the stack when a container ended.
I used std::shared_ptr for pointers, so there is no manual memory management. And the private value inside the object that held the actual values is not dynamically allocated; which meant the value would be destroyed if the object is destroyed.
Now that I had built a parser/serializer according to the JSON spec, I thought it would be a good idea to test it against some sophisticated test cases. So, I searched the internet and found this repository where they had a bunch of test cases.
With some code changes over a week, I was able to pass all the test cases.
I have also added functionality to pretty print JSON just like jq!.
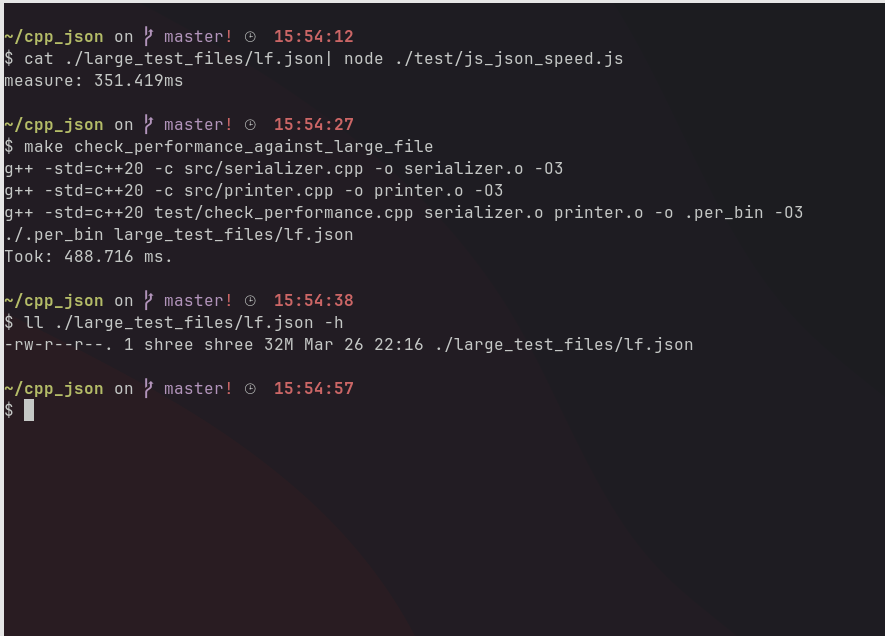
For small files, it surpasses JSON.stringify of JS in the speed of serialization. However, for too big strings: like > 20MB, it is slower than JSON.parse, but not too much. That’s because v8 used by JS heavily optimizes strings and I am using std::string in my program. A slight overhead is also added because of the use of smart_pointers.
Here is the parse speed comparison against JSON.parse for a large test file of ~ 32MB.
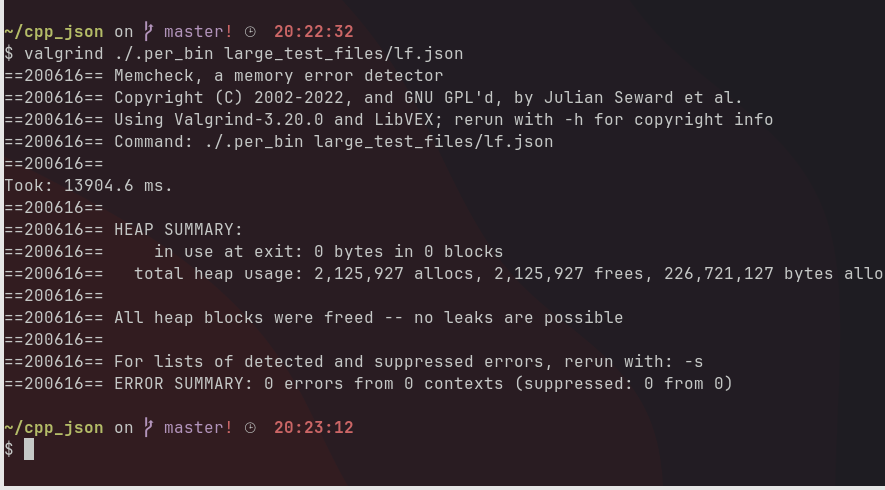
To make sure there aren’t any memory leaks, I made the parser parse the same 32MB file and ran the process through Valgrind. Thankfully, there weren’t any leaks.
I plan on improving the performance of the parser in the future. I tried to use raw pointers and manual memory management on a different branch, but it only bought an improvement of 10 ms. So, I abandoned the idea.